
Como restaurar apenas alguns objetos de um backup do SQL Server
Seja bem vindo!
[Início do Alerta de Spoiler]
Talvez este post não te ajude se você já estiver com um problema no qual precisa realizar esta tarefa, mas garanto que ele poderá te ajudar muito no futuro.
[Fim do Alerta de Spoiler]
Na época do lançamento do SQL Server 2008 foram adicionados muitas features e muita coisa mudou. Nessa época eu devorava muitos artigos sobre boas práticas, eu sinto um pouco de falta disso hoje em dia... O objetivo dos artigos técnicos mudaram um pouco na minha opinião... Mas vamos deixar de lado o sentimento de "no meu tempo que era bom" e vamos ao que interessa. Uma recomendação que guardei em minha memória é:
"Nunca utilize o filegroup "PRIMARY" para armazenar seus dados, ele deve conter apenas os metadados. Além do fato de que a saúde do seu banco se baseia na quantidade de páginas corrompidas no "PRIMARY"."
Ou seja, sempre crie um filegroup novo e o defina como sendo o default do seu banco.
Neste ponto, me reservo o direito de citar Galadriel no início de "The Lord of the Rings":
"A história virou lenda, a lenda virou mito e coisas que não deveriam ser esquecidas foram perdidas."
Desde sempre, DBA's SQL Server tem necessidade de efetuar o restore de apenas uma ou algumas procedures e/ou tabelas de um banco que tem Terabytes de dados. Essa necessidade pode surgir de qualquer lugar, desde um clássico "update sem where" em uma tabela super importante, até uma nova versão de procedure que retorna erro e que se descobre não ter a versão anterior do código. O fato é que mais hora, menos hora, você terá de lidar com estas situações em bancos de tamanho considerável!
Como você já deve saber, em um restore de um arquivo de backup do SQL Server não existe como definir quais tabelas ou procedures restaurar, mas é possível restaurar apenas um filegroup específico e este recurso esconde possibilidades valiosas para os cenários que descrevi anteriormente.
Antes de mais nada, explicarei o ambiente que montei, não colocarei em detalhes como o montei, mas, como sempre, fico a disposição para que me contate. Estou utilizando o banco do Stack Overflow, a versão que tem apenas 10GB, pois já é suficiente para as demonstrações. Apenas tratei ele para ter os seguintes filegroups e files:
 |
| Estrutra de "filegroups" e "files" |
E dentro deste banco existe a seguinte estrutura:
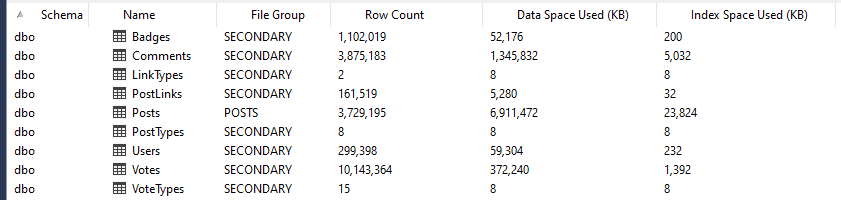 |
| Tabelas e espaços ocupados |
Note que minha maior tabela é de longe a tabela "Posts", uma vez que apenas ela ocupa aproximadamente 7GB. Veja também que não existe nenhuma tabela criada no filegroup "PRIMARY" pois o banco possui um filegroup que chamei de "SECONDARY" e o defini como o default. Todas as tabelas, exceto a "Posts", residem neste filegroup. Neste mesmo banco, criei a seguinte procedure:
 |
| Procedure original |
Que tem um retorno bem simples:
 |
| Retorno da procedure original |
Agora imagine que, após uma análise, um desenvolvedor entende que esta procedure é utilizada sempre levando em consideração apenas a parte de data e descartando a parte de hora. Então ele decide alterara-lá da seguinte forma:
 |
| Nova versão da procedure |
Aonde o novo retorno fica da seguinte forma:
 |
| Novo retorno da procedure |
Alterações feitas em produção, primeiro dia após a alteração aplicada, o desenvolvedor descobre que um dos módulos do sistema, justo aquele que não se tem mais o código fonte, utiliza esta procedure e precisa que o retorno contenha a parte de hora. O desenvolvedor também descobre que o código anterior desta procedure foi perdido no mesmo evento aonde se perdeu o código deste módulo, ou seja, a única opção é restaurar o último backup deste banco para poder gerar o script da versão anterior da procedure.
Imagine que fosse um banco de 10TB ao invés de apenas 10GB... Seria o caso de achar espaço em disco para alocar esse restore, se não fosse preciso acionar mais equipes além do DBA... De qualquer forma seria um processo demorado e possivelmente estressante.
Neste momento entra no jogo o restore parcial, uma feature que considero muito útil. Um fato que muitos DBA's não sabem, ou que nunca se perguntaram, é que todos os metadados de um banco ficam armazenados no filegroup "PRIMARY" (lembra o que mencionei no início do post?), que no banco que estou usando tem apenas 8MB. Juntando estes pontos, efetuei um restore parcial apenas do filegroup "PRIMARY", veja o comando abaixo e seu retorno:
 |
| Comando de restore parcial |
 |
| Retorno do restore parcial |
Ao verificar os arquivos em disco, existem apenas os arquivos do filegroup "PRIMARY" e o arquivo de transaction log:
 |
| Arquivos em disco |
Agora é apenas ir no "Object Explorer" e efetuar o "Generate Script" da versão anterior da procedure:

Ou seja, ao invés de restaurar um backup completo que tem aproximadamente 10GB, foi possível resolver a questão com um restore de apenas 8MB. Agora que você conhece este recurso, vamos imaginar que nesta mesma manutenção que alterou a procedure, o DBA executou um script para alterar alguns registros na tabela "Users", porém na hora que selecionou o código para execução, deixou de fora o where e não percebeu. Sendo assim, além da procedure causando problemas, você tem dados errados em sua produção.
Neste caso vou aplicar a mesma estratégia, porém, agora tenho como objetivo retornar apenas a tabela "Users" antes da alteração equivocada. Esta tabela não está em um filegroup dedicado, como a tabela "Posts" se encontra, ela está no filegroup "SECONDARY" junto com algumas outras tabelas. Não é exatamente um problema, pois ainda serão restaurados apenas 2GB frente aos 10GB totais do banco.
Uma informação interessante é que eu posso "adicionar" este outro filegroup ao meu banco que já existe:
 |
| Restore do filegroup "SECONDARY" |
 |
| Retorno do restore do filegroup "SECONDARY" |
Note que eu não adicionei a opção de "replace" ou seja, o banco que criei inicialmente para recuperar a procedure não foi sobreposto, foi apenas adicionado a ele o filegroup "SECONDARY":
 |
| Arquivos em disco |
Com isso você poderá ler tranquilamente tabela "Users" antes do update sem where:
 |
| Lendo a tabela "Users" |
"Igor, mas e o que acontece se eu tentar ler a tabela "Posts"?" Bom, a mensagem é autoexplicativa:
 |
| Lendo a tabela "Posts" |
Concluindo, a organização de filegroups dentro do SQL Server é um ponto bem importante. Ele deve ser levado em consideração quando criamos um banco de dados e ao longo do tempo quando este começa a ter um volume de dados considerável. Com a estratégia que apresentei aqui, é possível sim realizar o restore de apenas alguns objetos, quando se tem o trabalho prévio de organização.
Até logo e obrigado pelos peixes!
Sensacional
ResponderExcluirMuito bom.
ResponderExcluirExcelente post postre Igor, "simples" e extremamente objetivo.
ResponderExcluir