
Aplicando conceitos do Google Site Reliability Engineering (SRE) no Microsoft SQL Server usando Splunk
Olá pessoal!
Atualmente estou lendo o livro do Google sobre "Site Reliability Engineering", que se encontra disponível para leitura online gratuita. No capítulo 4 , "Service Level Objectives", é abordada uma métrica para o tempo de resposta de "Get RPC calls". O que mais gostei na abordagem apresentada é que ela não define um número único como métrica, aonde comparamos se o valor atual está acima ou abaixo deste número. Ao invés disso é utilizado um conceito de faixas que se sobrepõem:
 |
| Site Reliability Engineering - Edited by Betsy Beyer, Chris Jones, Jennifer Petoff and Niall Richard Murphy |
Achei muito interessante e comecei a pensar em como eu coletaria este tipo de informação no Microsoft SQL Server. Logo pensei no SQLdiag, pois ele seria muito útil para coletar este tipo de contador de performance, caso ele existisse, obviamente. Porém, como eu costumo dizer, o Diag é uma ferramenta feita para necrópsia, não para monitoria, menos ainda para uma que teria que idealmente ser em tempo real.
Então, vamos ao primeiro passo.
Contadores de performance
Minha primeira parada, obviamente, foi no meu velho amigo perfmon do Microsoft Windows. Eu tinha no fundo da minha memória a vaga lembrança de um contador relacionado a tempo, porém não lembrava exatamente qual tempo, se era de execução, de lock, etc.
Nessa empreitada, encontrei os seguintes contadores:
 |
| Perfmon counters para minha instance |
Pareciam bem aderentes ao que eu pretendia, mas fiz um double check na documentação oficial do contador "Batch Resp Statistics". Aonde temos a seguinte definição:
 |
| Batch Resp Statistics |
Sendo assim, decidi que focaria na instance "Elapsed Time:Total(ms)", pois me parecia ser a mais indicada para meu objetivo.
Na sequência, realizei alguns testes utilizando a ferramenta HammerDB para gerar algumas cargas em minha máquina de testes. O uso desta ferramenta está fora do escopo deste artigo, mas caso queira maiores informações sobre ela, pode me contatar.
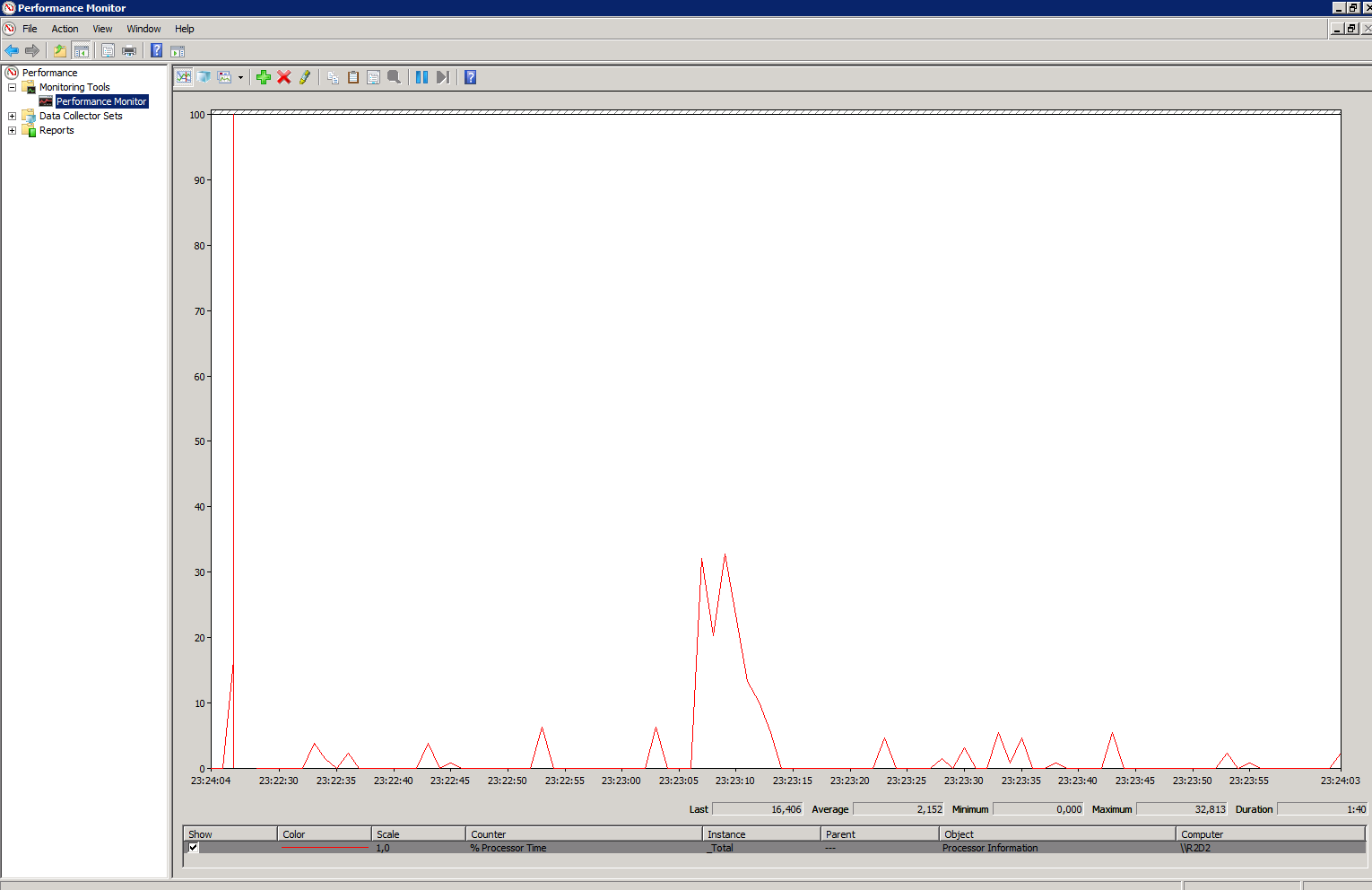
Efetuei alguns testes de carga para averiguar o comportamento do contador:
 |
| Amostra de coleta |
Ao que parece, este contador funciona somente incrementando valores, sendo assim, havia a necessidade de calcular a diferença dos valores dos contadores entre a coleta atual e a coleta anterior. O Diag faz maravilhas, mas decididamente não era a ferramenta para este caso.
Dentro do próprio Microsoft SQL Server, com Transact-SQL, seria facilmente realizável um processo deste tipo, porém estes contadores são de perfmon que é uma ferramenta do Microsoft Windows. Então como resolver?
Perfmon dentro do Microsoft SQL Server?
O que muita gente não sabe é que dentro do Microsoft SQL Server, temos uma DMV que endereça este ponto, a "sys.dm_os_performance_counters". Ela, como o próprio nome indica, é uma interface entre o Microsoft SQL Server e o sistema operacional para obtenção de valores de contadores de performance. Para quem já teve curiosidade de olhar o Diag para Microsoft SQL Server em Linux, pôde perceber que grande parte dos contadores de Microsoft SQL Server, que normalmente coletaríamos via perfmon no Microsoft Windows, são coletados via esta DMV no Linux.
Confirmei que os contadores de "Batch Resp Statistics" existem na "sys.dm_os_performance_counters", com este fato, era questão de gerar um script para executar as coletas e calcular a diferença dos valores entre as mesmas.
Para este fim, criei a procedure "usp_batch_resp_statistics", simples como a vida deve ser. No meu caso eu dividi minhas "requests" da seguinte forma:
- Batch time >=000000ms e <000100ms
- Batch time >=000000ms e <000200ms
- Batch time >=000000ms e <000500ms
Ou seja, supus que meu sistema tem o seguinte "Service Level Objective (SLO)":
- 90% dos batches devem ter seu tempo total de duração >=000000ms e <000100ms
- 99% dos batches devem ter seu tempo total de duração >=000000ms e <000200ms
- 99.9% dos batches devem ter seu tempo total de duração >=000000ms e <000500ms
Feito isto, a procedure para coletar as informações ficou com o seguinte resultado:
 |
| Retorno da procedure usp_batch_resp_statistics |
Agora, o ponto é como armazenar e exibir estes dados?
Splunk coletando dados e exibindo gráficos
Naturalmente, a primeira opção para qualquer DBA seria colocar a coleta em um job do Microsoft SQL Server Agent, agendar a execução a cada X tempo e salvar os dados em uma tabela do próprio Microsoft SQL Server. Não há nada de errado nesta abordagem, porém eu resolvi juntar o útil ao agradável e efetuar o teste de uma ferramenta que estava na fila de estudos. Por isso decidi utilizar o Splunk.
Eu já havia estudado brevemente como coletar dados do Microsoft SQL Server através do Splunk, então decidi colocar em prática o pouco que eu sabia. Vou deixar fora deste artigo os pormenores da ferramenta, mas, novamente, caso queira conversar sobre ela, entre em contato. De forma macro, estes foram os passos que executei:
Eu já havia estudado brevemente como coletar dados do Microsoft SQL Server através do Splunk, então decidi colocar em prática o pouco que eu sabia. Vou deixar fora deste artigo os pormenores da ferramenta, mas, novamente, caso queira conversar sobre ela, entre em contato. De forma macro, estes foram os passos que executei:
- Baixar e instalar o Splunk. Optei por uma instalação em Microsoft Windows Server 2012 R2 pois já tinha uma VM pronta.
- Baixar e instalar o Splunk Add-on for Microsoft SQL Server, também chamado de Splunk DB Connect. A instalação deste componente, após seu download, é realizada por dentro do próprio portal do Splunk.
- Baixar o Microsoft JDBC Driver for SQL Server. Este item não é instalado, deve-se colocar o arquivo ".jar" em um pasta dentro da estrutura do Splunk e o mesmo é reconhecido pela ferramenta.
- Criar uma identidade para utilizar na conexão. No meu caso utilizei uma conta SQL Login.
- Criar uma conexão com o servidor de banco de dados Microsoft SQL Server. O de sempre: servidor, porta, usuário, senha e base de dados padrão.
- Criar uma coleta que execute a procedure previamente mencionada. Aqui existem dois pontos que eu gostaria de salientar:
- Eu criei minha coleta para execução a cada 30 segundos, talvez este tempo seja inviável para um ambiente de produção, mas para meu ambiente de testes me pareceu pertinente.
- A versão do Splunk DB Connect que utilizei para estas atividades parece ter um bug no momento da redação deste post. Tive que criar minha coleta via arquivo de configuração "db_inputs.conf", pois via portal retornava erro. Uma vez criada a coleta, a edição via portal funcionou perfeitamente.
Splunk coletando os dados, efetuei o seguinte procedimento utilizando o HammerDB:
Meu objetivo era simular momentos de carga baixa, carga normal e sobrecarga a fim de verificar variações nas métricas coletadas. No final o gráfico gerado foi :
- Criei um banco de dados do HammerDB com 25 Warehouses.
- Iniciei a coleta de dados no Splunk.
- Iniciei uma carga com 10 Virtual Users no HammerDB, a qual considerei como uma carga baixa para o ambiente em questão.
- Após 5 minutos, iniciei outra carga com 40 Virtual Users no HammerDB, totalizando 50 Virtual Users, a qual considerei como uma carga regular para o ambiente.
- Após 5 minutos, iniciei outra carga com 50 Virtual Users no HammerDB, totalizando 100 Virtual Users, a qual considerei como uma carga alta para o ambiente.
- Depois disso, parei as cargas a cada 5 minutos, primeiro a de 50, depois a de 40 e por fim a de 10 Virtual Users.
Meu objetivo era simular momentos de carga baixa, carga normal e sobrecarga a fim de verificar variações nas métricas coletadas. No final o gráfico gerado foi :
 |
| Gráfico no Splunk |
Efetuando uma análise mais profunda do gráfico:
 |
| Gráfico com quadrante de tempo de resposta |
Nas regiões dos quadrados verdes a situação foi bem confortável durante a carga de apenas 10 Virtual Users .
Nas regiões dos quadrados amarelos, com a carga adicional de 40 Virtual Users, totalizando 50 Virtual Users, alguns batches ficaram acima de 100ms, mas abaixo de 200ms.
Na primeira região do quadrado vermelho, em torno de 75% dos batches responderam abaixo de 100ms e alguns ficaram acima dos 200ms. Com o SLO mencionado anteriormente aonde "90% dos batches devem ter seu tempo total de duração >=000000ms e <000100ms", seria necessária alguma ação para mitigar o impacto para os consumidores do serviço. Seja uma automação ou o acionamento de um analista para trabalhar no caso.
A região do segundo quadrado vermelho foi surpresa para mim, não simulei este fato intencionalmente, mas seria uma situação bem crítica pois algo em torno de apenas 25% dos batches responderam abaixo de 100ms.
Ter esse tipo de estatísticas e métricas do seu ambiente me parecem bem úteis. Imaginando o dia a dia, um dos grandes desafios é saber o que seria o comportamento regular do ambiente e como perceber, com a máxima acurácia, quando temos ou teremos um problema.
Até logo e obrigado pelos peixes!
Nas regiões dos quadrados amarelos, com a carga adicional de 40 Virtual Users, totalizando 50 Virtual Users, alguns batches ficaram acima de 100ms, mas abaixo de 200ms.
Na primeira região do quadrado vermelho, em torno de 75% dos batches responderam abaixo de 100ms e alguns ficaram acima dos 200ms. Com o SLO mencionado anteriormente aonde "90% dos batches devem ter seu tempo total de duração >=000000ms e <000100ms", seria necessária alguma ação para mitigar o impacto para os consumidores do serviço. Seja uma automação ou o acionamento de um analista para trabalhar no caso.
A região do segundo quadrado vermelho foi surpresa para mim, não simulei este fato intencionalmente, mas seria uma situação bem crítica pois algo em torno de apenas 25% dos batches responderam abaixo de 100ms.
Conclusão
Ter esse tipo de estatísticas e métricas do seu ambiente me parecem bem úteis. Imaginando o dia a dia, um dos grandes desafios é saber o que seria o comportamento regular do ambiente e como perceber, com a máxima acurácia, quando temos ou teremos um problema.
Até logo e obrigado pelos peixes!
Comentários
Postar um comentário